


Sure! Here’s the translation into American English:
—
Research universities dedicated to artificial intelligence (AI) and high-performance computing (HPC) face significant challenges due to the complexity of their infrastructure. These challenges include long GPU acquisition cycles, rigid scalability limits, and complicated maintenance requirements, which hinder the agile work of researchers in key areas such as natural language processing and computer vision.
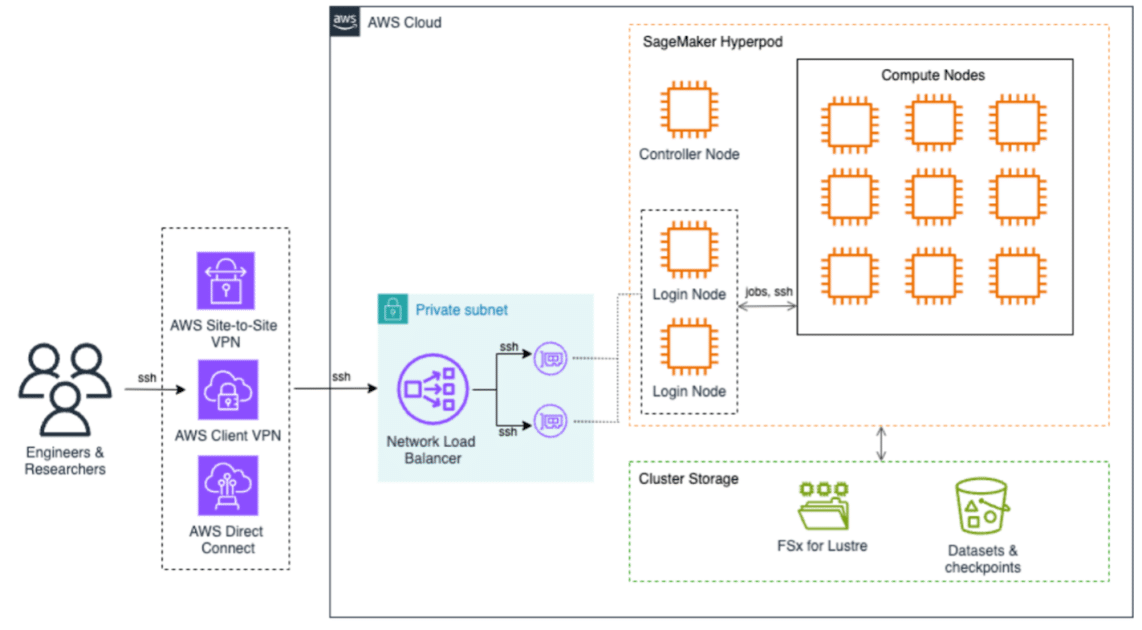
To address these issues, Amazon has introduced SageMaker HyperPod, a solution designed to relieve the operational burden of building AI models. This system enables rapid scalability in activities like training, optimizing, and inferring models, relying on a cluster that can include hundreds or even thousands of AI accelerators, such as NVIDIA H100 or A100 GPUs.
Recently, a research university implemented this system in order to accelerate its work in AI. By using dynamic SLURM partitions and precise GPU resource management, researchers were able to carry out their work without the setbacks that accompany traditional infrastructures. This architecture not only improves access to the necessary tools but also facilitates tracking of computational costs and load balancing among access nodes.
The SageMaker HyperPod infrastructure is fully managed through AWS, which minimizes operational effort and maximizes security and performance. Users access this platform through secure connection options that optimize traffic and enhance interaction with the cluster.
Regarding storage infrastructure, it is built on two fundamental components: Amazon FSx for Lustre and Amazon S3. The former provides a high-performance file system, while the latter handles the secure storage of datasets and checkpoints, facilitating access to the information needed for model training.
The implementation of SageMaker HyperPod took place in several phases, starting with configuring the AWS infrastructure and then customizing the SLURM cluster settings to meet the department’s research needs. This included enabling Generic Resource (GRES) configuration, which optimizes GPU access by allowing multiple users to utilize them simultaneously without conflicts.
To ensure efficiency and cost control, each resource in the SageMaker HyperPod was assigned a unique identifier, allowing for monthly expense tracking through tools like AWS Budgets and AWS Cost Explorer. Additionally, a load balancing system for access nodes was implemented, ensuring smooth resource access for multiple users in parallel.
Finally, an Active Directory system was integrated to provide secure access for researchers, ensuring unified control over users’ identities and privileges. Thanks to these implementations, the use of SageMaker HyperPod promises to transform computing in the academic realm, enabling institutions to accelerate innovation in AI and focus on their scientific goals rather than dealing with the complexities of traditional infrastructures.
—
Let me know if you need further assistance!
via: MiMub in Spanish