


In the context of generative artificial intelligence applications, response speed has become as essential as the quality of the models themselves. Latency, or the time it takes a system to process a request and return a response, can significantly impact the operability of different sectors. From customer service teams handling urgent inquiries to programmers seeking instant code suggestions, every second counts. This dynamism requires companies implementing large language models (LLMs) to face the challenge of maintaining agile performance, balancing speed with quality results.
Latency is not just a mere inconvenience; its effect extends to the user experience. In interactive artificial intelligence applications, a slow response can disrupt the natural flow of interaction, decrease user engagement, and ultimately affect the adoption of AI-driven solutions. This challenge is further accentuated by the increasing complexity of modern LLM applications, where multiple interactions with the model are often required to resolve a single query, contributing to increased response times.
During the re:Invent 2024 event, Amazon introduced a new inference functionality optimized to reduce latency in its foundation models (FMs) through Amazon Bedrock. This innovation promises to significantly reduce latency in models like Anthropic’s Claude 3.5 Haiku and Meta’s Llama 3.1, compared to their conventional versions. This optimization is particularly relevant for workloads where response speed is critical, directly impacting the effectiveness of business operations.
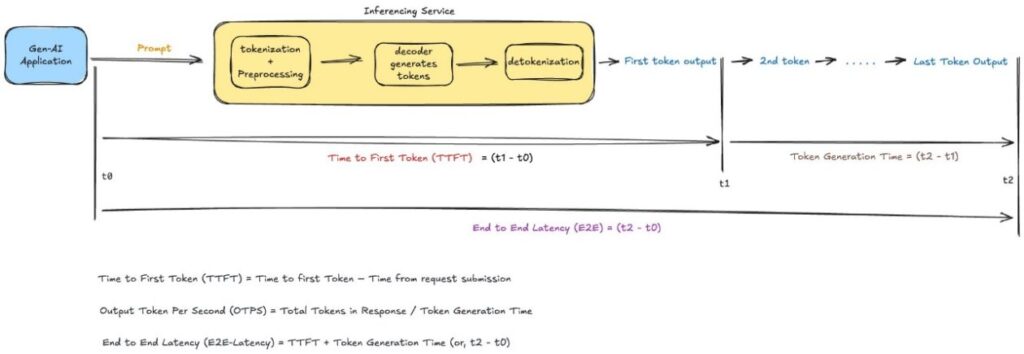
Improvements in latency focus not only on raw speed but also on offering a smoother user experience in applications using LLMs. The concept of latency is presented as multifaceted, encompassing various elements such as time to first token (TTFT), which measures how quickly an application starts responding after receiving a question, and various other aspects related to processing and delivering accurate and fast responses. With these innovations, companies are positioning themselves to better meet user expectations in an increasingly competitive and AI-dependent world.
Referrer: MiMub in Spanish