


Here’s the translation into American English:
—
Chat assistants powered by Retrieval-Augmented Generation (RAG) are transforming the landscape of customer support, internal inquiries, and business search. This innovative technology enables quick and accurate responses by utilizing internal company data, which is essential for enhancing the user experience. Through RAG, it is possible to use a base model that is ready for deployment and enrich it with specific information from each organization. This ensures that responses are relevant and contextualized, eliminating the need for complicated adjustments or retraining.
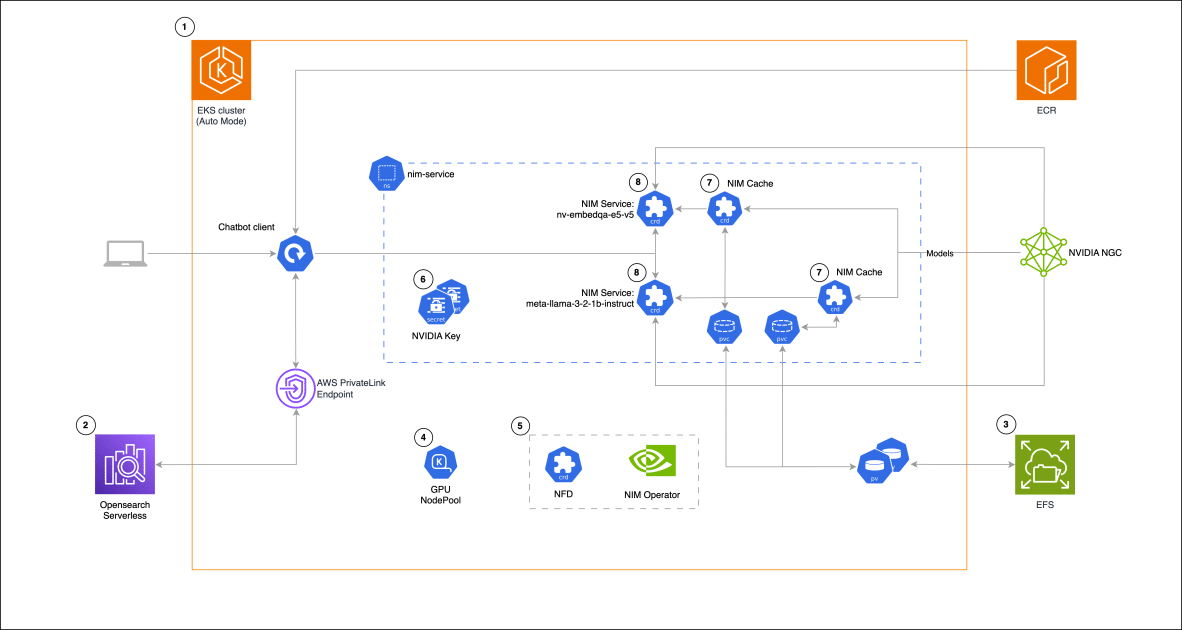
The integration of Amazon Elastic Kubernetes Service (EKS) to operate these assistants provides great flexibility and complete control over the data and infrastructure used. EKS can adapt to various workloads, making it a cost-effective option for both steady and fluctuating demands. Its compatibility with applications in Kubernetes environments, whether on-premises or in the cloud, facilitates deployment across different platforms.
On the other hand, NVIDIA NIM microservices simplify the deployment of artificial intelligence models by integrating with other Amazon Web Services (AWS) like Amazon EC2, EKS, and SageMaker. These microservices, distributed in Docker containers, eliminate the complexity of managing AI models, automating technical configurations that would otherwise require time and engineering expertise.
Moreover, the NVIDIA NIM operator streamlines the management of components and services in Kubernetes, allowing different models to operate efficiently. Its architecture enables coordinated resource management, which helps reduce inference latency and enhances automatic scalability capabilities.
In a practical case, a RAG chat assistant has been developed using NVIDIA NIM for language model inference, combined with Amazon OpenSearch Serverless for storing and querying high-dimensional vectors. This structure, enabled in Kubernetes thanks to EKS, facilitates the efficient deployment of heterogeneous computing workloads.
The creation of this solution involves a process that ranges from configuring the EKS cluster and OpenSearch Serverless to establishing an EFS file system and creating node groups with GPUs using Karpenter. Each step is aimed at optimizing performance and cost efficiency, integrating tools that facilitate model management and ensuring that responses are both fast and accurate.
Finally, the implementation of a chat assistant client employs libraries like Gradio and LangChain to provide an intuitive interface. This system allows the assistant to retrieve relevant information and generate contextual responses, demonstrating that Amazon EKS is an effective solution for deploying artificial intelligence applications, ensuring the reliability and scalability needed to meet current challenges in the business realm.
via: MiMub in Spanish