


Certainly! Here’s the translation into American English:
—
With the increase in unstructured data volumes in the insurance industry, companies are facing significant challenges in processing and analyzing this information. Documents such as claims, accident videos, and chat transcripts contain crucial information throughout the claims processing cycle, but traditional preprocessing methods often lack the necessary accuracy and consistency. This limits the effectiveness of metadata extraction and the use of data for artificial intelligence applications, such as fraud detection and risk analysis.
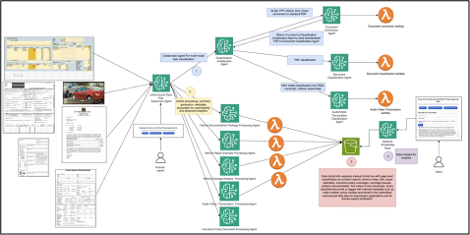
In response to these challenges, an innovative system for collaboration among multiple agents has been proposed. This approach involves a set of specialized agents focused on different tasks such as classification, conversion, and metadata extraction. By orchestrating these agents, the aim is to automate the ingestion and transformation of unstructured data from various formats, thereby improving accuracy and efficiency in end-to-end analyses.
While a single-agent setup may suffice for teams handling small volumes of homogeneous documents, the diversity of data in claims packages or collision videos requires the advantages of a multi-agent architecture. This not only allows for better engineering in creating prompts and more effective debugging but also optimizes information extraction according to the nature of each type of data.
As the variety and amount of data increase, this modular design offers efficient scalability. It allows for the integration of new agents or the enhancement of existing ones without disrupting the overall flow. Feedback from experts can be incorporated during human intervention, promoting continuous improvement of the system.
This approach can be supported by Amazon Bedrock, a service that facilitates the creation of generative artificial intelligence applications. This platform enables the configuration of intelligent agents capable of retrieving context from knowledge bases and orchestrating complex tasks. Its flexibility is key to processing large amounts of unstructured data and adapting to changes in workflows.
The system is designed as a preprocessing hub for unstructured data, including functionalities such as incoming data classification, metadata extraction, and human validation to correct uncertain fields. This culminates in a data lake rich in metadata, establishing a solid foundation for fraud detection and advanced analytics.
The modularity of the system allows each agent to manage specific functions, which not only promotes more scalable management but also reduces the time spent on human validation and enhances accuracy in data extraction. Continuous integration of experts during the validation phase ensures ongoing improvements in the quality and structure of information over time.
In summary, transforming unstructured data into rich metadata outputs presents companies with the opportunity to accelerate critical processes, optimize customer management, and make informed decisions based on advanced analyses. It is anticipated that as this agent collaboration system evolves, the need for human intervention will be significantly reduced, enhancing automation and solidifying its role in the future of claims processing in the insurance sector.
Source: MiMub in Spanish