


Sure! Here’s the translation to American English:
With the growing popularity of artificial intelligence solutions, a recurring concern among clients arises: how much will it cost to implement a chatbot using Amazon Bedrock? Understanding the associated costs is crucial for project planning and budgeting in a realm where metrics and pricing models tend to be complex.
Amazon Bedrock is presented as a fully managed service that allows users to access a variety of high-performance foundational models created by leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, and Stability AI. Through a single API, this service offers a comprehensive set of tools that facilitate the development of generative AI applications, ensuring both security and respect for data privacy.
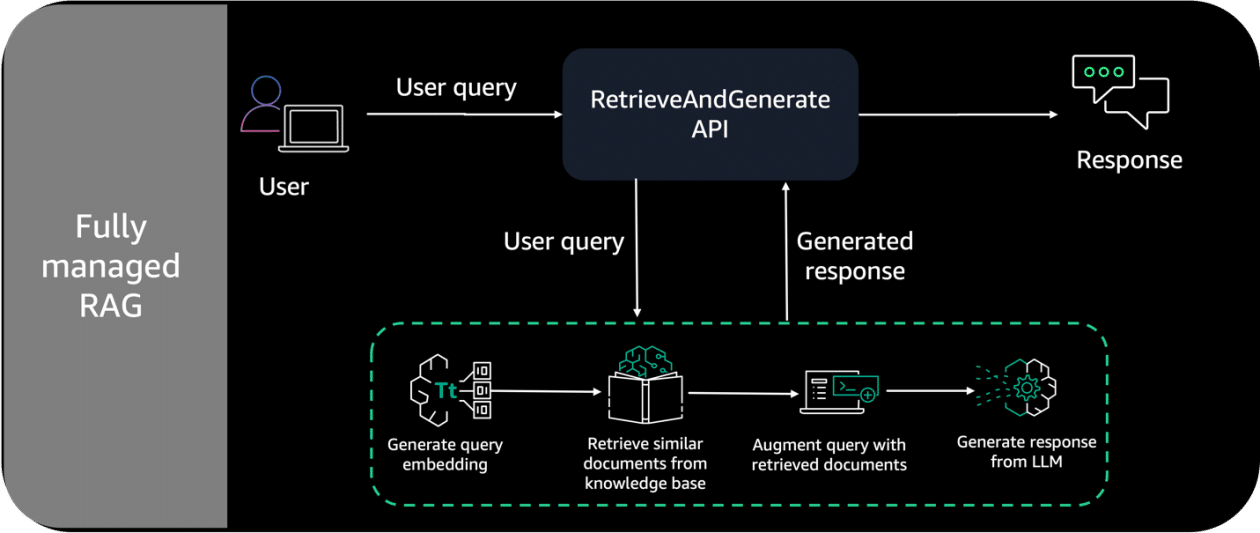
To illustrate the pricing model of Amazon Bedrock, a practical case related to the development of a customer service chatbot is proposed. In this scenario, various cost components are analyzed, such as the use of data sources, retrieval-augmented generation (RAG), as well as the number of tokens and context windows, which directly influence the final cost of the service.
The chatbot is planned to use a curated dataset and apply RAG to obtain relevant real-time information. This approach aims to enrich the chatbot’s responses, thereby enhancing the user experience. To calculate the necessary budget, it’s crucial to understand different factors, such as the volume of user inquiries and the features of the available natural language models.
The model aims to establish a customer service center that processes up to 10,000 inquiries per month, with query lengths fluctuating between 50 and 200 tokens. This volume of inquiries will generate considerable token usage for the chatbot’s responses, in addition to requiring appropriate infrastructure to support a large number of simultaneous users.
When analyzing the total cost of ownership (TCO) in a pay-as-you-go pricing model, both model inference and vector storage costs are considered. Prices vary based on the chosen models, from more economical options to high-performance ones. For example, the embedding costs for the Amazon Titan and Cohere models show notable differences based on the cost per thousand tokens.
Despite the apparent complexity in estimating costs for AI solution implementation, it’s possible not to feel overwhelmed. Evaluating key components, comparing different models, and understanding capacity requirements can significantly simplify the task. The implementation of Amazon Bedrock offers the flexibility needed to select the most suitable model and pricing structure, thereby optimizing both performance and costs.
For those interested in delving into the world of generative AI and enhancing their customer service, Amazon Bedrock presents itself as a viable and promising option.
via: MiMub in Spanish