


The optimization of generative artificial intelligence applications is constantly evolving, driven by techniques that seek to personalize base models more efficiently. Among these techniques are prompt engineering, document retrieval, continuous pretraining, and fine-tuning, which are essential for maximizing value and reducing resource demands during model training.
Recently, an innovative approach known as Spectrum has been introduced, focusing on identifying the most informative layers of a base model. This approach allows for selective fine-tuning, improving training efficiency by focusing on layers that truly add value. Furthermore, methods have been developed to achieve more effective fine-tuning, such as the Quantized LoRA (QLoRA) technique, which combines low-range adaptation with quantization of the original model. Although QLoRA has proven effective in resource savings, its implementation is applied superficially across the entire model.
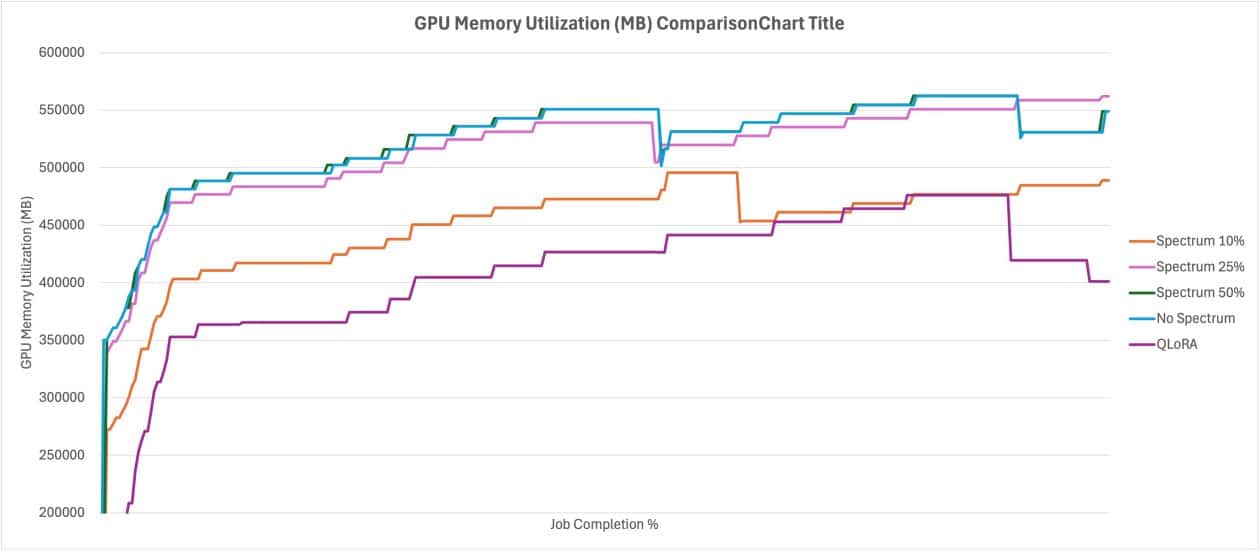
Using Spectrum not only optimizes resource utilization but also shortens training times, all without compromising the quality of the resulting model. This approach can be applied on platforms like Amazon SageMaker AI, where the benefits and drawbacks between Spectrum and QLoRA are analyzed. While QLoRA offers advantages in terms of resources, Spectrum stands out for its superior performance.
The operation of Spectrum in fine-tuning involves a comprehensive evaluation of weight matrices across the model layers, calculating the Signal-to-Noise Ratio (SNR) of each. Instead of training all layers, Spectrum selects a subset with full precision based on its SNR, while the rest of the model is frozen. This allows for training with various precisions, adapting to the capabilities of modern GPUs.
This approach is supported by Random Matrix Theory and the Marchenko-Pastur distribution to effectively differentiate between signal and noise. Through a configurable percentage, Spectrum identifies the most informative layers to focus fine-tuning on.
A practical case will be presented demonstrating the application of Spectrum in fine-tuning the Qwen3-8B model, using Amazon SageMaker. This process involves several key stages, from downloading the model and evaluating its SNR, to creating a file determining which layers should be used during training.
To carry out this process, it is essential to have an AWS account equipped with the necessary permissions to create resources in SageMaker, as well as configure Amazon SageMaker Studio to run code in a Jupyter environment. Additionally, it will be necessary to clone the Spectrum repository and run analysis scripts to identify the most influential layers.
The analysis will result in files detailing the SNR of the layers and specifying those that should remain active during training. This information allows for optimizing the fine-tuning process, ensuring that resources are directed to the most relevant layers.
In conclusion, Spectrum represents a significant advancement in reducing the resources needed for fine-tuning base models, shortening training times without sacrificing accuracy. This innovation offers new opportunities in optimizing artificial intelligence models, enabling a more effective approach to critical learning layers.
via: MiMub in Spanish