


Sure! Here’s the translation into American English:
—
Organizations are increasingly incorporating foundation models (FMs) into their artificial intelligence and machine learning (AI/ML) operations, highlighting the need to efficiently manage large-scale inference operations. With this premise, Amazon Bedrock has positioned itself as a key solution, offering two inference patterns: real-time and batch. Batch inference becomes a particularly valuable option for handling large volumes of data that do not require immediate results.
This method stands out for its cost-effectiveness, offering a 50% discount compared to on-demand processing, making it ideal for high-volume workloads that can afford a certain margin of time. However, developers face challenges in its implementation, such as managing input format, job quotas, and orchestrating concurrent executions. To address these complexities, a robust framework is needed to facilitate the execution of these operations.
Recently, a scalable and flexible solution has been introduced that simplifies the batch inference workflow. This approach allows for the effective management of batch inference requests from FMs, such as generating embeddings for millions of documents or conducting evaluations with large datasets.
The system architecture is structured in three main phases: first, preprocessing the input datasets; second, executing batch inference jobs in parallel; and third, post-processing to analyze the results generated by the model. With a simple configuration input, AWS Step Functions takes care of preparing the dataset, launching jobs in parallel, and managing the post-processing of outputs.
A practical case illustrating the effectiveness of this solution is the analysis of 2.2 million rows from the SimpleCoT dataset. This set is designed to train chain-of-thought (CoT) reasoning in language models, encompassing various issues from reading comprehension to logical reasoning.
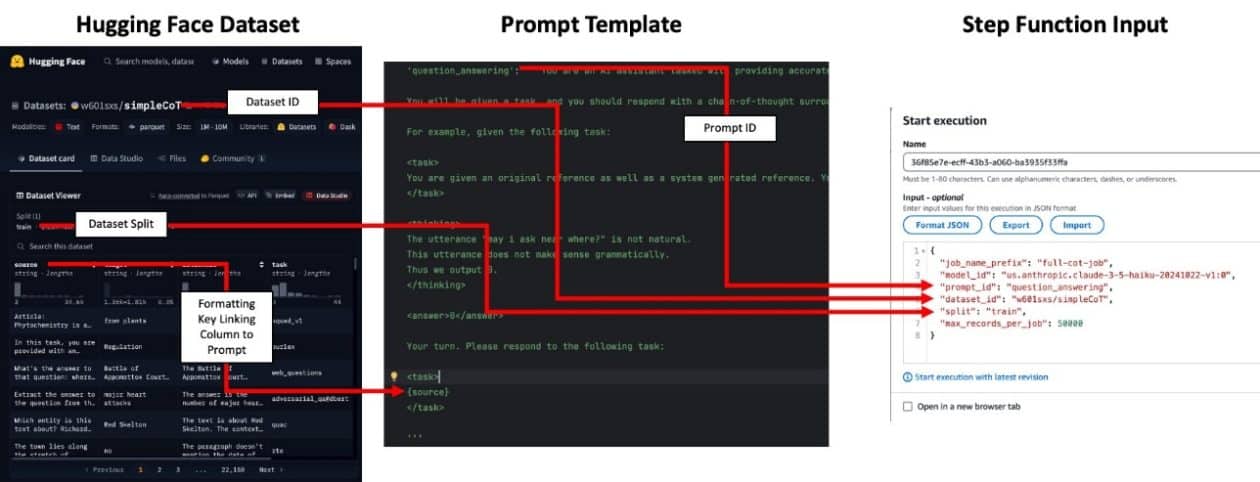
The batch orchestration solution employs scalable, serverless components, catering to the architectural particulars of batch processing workflows. Job inputs must be in JSONL format and stored in an Amazon S3 bucket, considering the necessary quotas for each dataset. Moreover, Step Functions plays a crucial role in coordinating long-running jobs, while Amazon DynamoDB manages the state of each process.
When generating embeddings or text responses, a prompt identifier is generally not required, although it is essential for the input files to contain the appropriate columns. During the execution of Step Functions, the process organization is facilitated, ensuring that outputs are correctly joined with the original input data.
The implementation of this solution gives companies the opportunity to explore a serverless architecture for data-intensive processing, effectively facilitating synthetic data generation and labeling. The solution is already available in a GitHub repository, and developers are expected to adapt it to their specific needs.
Referrer: MiMub in Spanish