


Here’s the translation to American English:
Artificial intelligence (AI) agents are playing a crucial role in customer service workflows across various industries, facilitating the automation of complex tasks and enhancing decision-making. However, their integration into production systems requires scalable evaluation pipelines that allow for measuring their performance in specific actions. This evaluation is critical, as it provides valuable insights that improve safety, control, trust, transparency, and the optimization of these systems’ performance.
Amazon Bedrock Agents benefit from the foundation models (FMs) available in Amazon Bedrock, along with APIs and data, to break down user requests, gather relevant information, and execute tasks efficiently. This means that teams can focus on higher-value activities by automating processes that require multiple steps.
In this context, Ragas, an open-source library, has been designed to test and evaluate applications of large language models (LLMs) across various use cases, such as retrieval-augmented generation (RAG). This framework allows for quantitatively measuring the effectiveness of RAG implementation and has recently been used to assess the RAG capabilities of Amazon Bedrock Agents.
The methodology known as LLM-as-a-judge involves using LLMs to evaluate the quality of outputs generated by AI, acting as an impartial evaluator. This approach has been used to analyze and score the text-to-SQL conversion capabilities and chain reasoning of Amazon Bedrock agents.
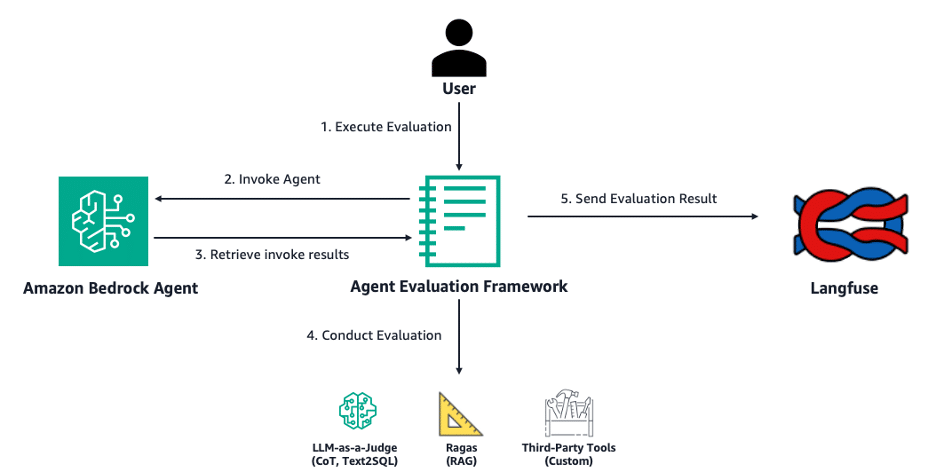
Meanwhile, Langfuse, another open-source engineering platform for LLMs, offers features such as traces, evaluations, request management, and metrics that help debug and enhance LLM-based applications. Recently, an evaluation framework for Bedrock agents has been introduced, allowing for assessment of their performance in RAG tasks, text-to-SQL conversion, and utilization of custom tools. A significant aspect of this advancement is the ability to visualize results and trace data through dashboards integrated within Langfuse.
Evaluating agents presents several technical challenges. Developers must face the difficulty of conducting a comprehensive evaluation that considers specific metrics and managing experiments due to the multiple possible configurations of agents. To simplify this process, the Open Source Bedrock Agent Evaluation framework enables users to specify an agent ID and run evaluation jobs that invoke agents in Amazon Bedrock. This procedure generates invocation traces that are analyzed and assessed, sending the results to Langfuse for insights and aggregated metrics.
The relevance of this evaluation becomes particularly notable in the field of pharmaceutical research, where agents have been designed to collaborate and analyze data related to biomarkers. These agents, using a collaborative methodology, facilitate the discovery of key information in medical research, making the integration and evaluation of their capabilities essential to ensure their performance. This underscores the need for effective tools for the evaluation of AI agents, which not only improve their efficacy but also ensure their trustworthiness and safety in critical environments.
Referrer: MiMub in Spanish