
Here’s the translation of your text into American English:
Salesforce and Amazon Web Services (AWS) have announced a collaboration aimed at optimizing the deployment of artificial intelligence models, highlighting the importance of large language models (LLMs). The Model Serving team at Salesforce focuses on developing and managing services that facilitate the integration of machine learning algorithms into critical applications, seeking to create a robust infrastructure for these purposes.
One of the major challenges faced by this team is achieving efficient deployment of the models, ensuring optimal performance and effective cost management. This process is particularly complicated by the wide variety of model sizes and performance requirements, which can range from a few gigabytes to up to 30 GB.
Experts have identified two key challenges. First, it has been observed that larger models tend to be used inefficiently, resulting in suboptimal use of multi-GPU instances. On the other hand, mid-sized models require low-latency processing, but this translates into higher costs due to resource over-provisioning.
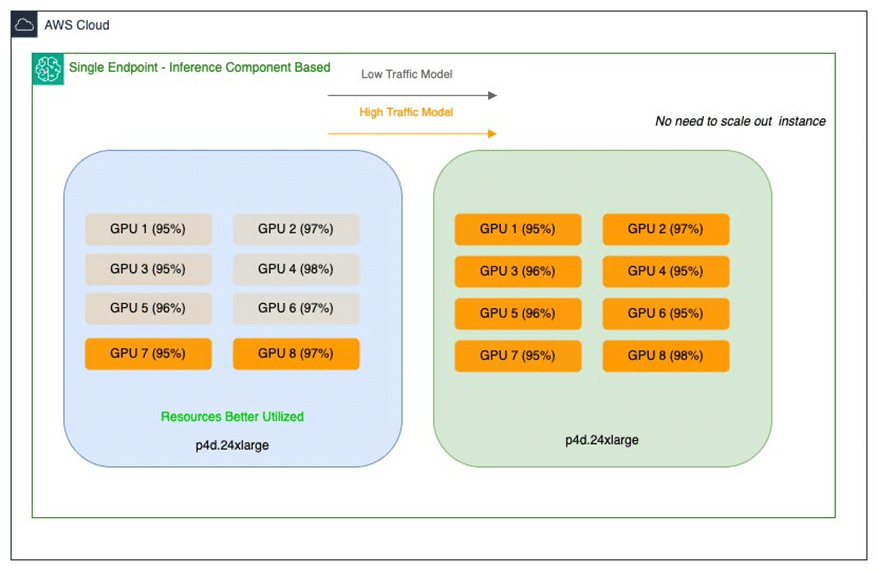
To address these issues, Salesforce has adopted inference components from Amazon SageMaker, allowing the deployment of multiple base models on a single SageMaker endpoint. This strategy facilitates more detailed control over the number of accelerators and the memory allocated to each model, thereby improving resource utilization and reducing associated costs.
The implementation of these components not only optimizes GPU usage but also allows models to scale independently according to the specific needs of each application. In this way, immediate deployment issues are addressed, and a flexible foundation is established to support the evolution of Salesforce’s artificial intelligence initiatives.
Thanks to these solutions, the company has achieved significant reductions in its infrastructure costs, realizing savings of up to 80% in deployment expenses. Additionally, this optimization benefits smaller models, enabling them to access high-performance GPUs, which enhances their performance and reduces latency time without incurring excessive costs.
Looking ahead, Salesforce plans to leverage the continuous update capabilities of these inference components, allowing them to keep their models up to date more efficiently, minimizing operational burdens and fostering the integration of future innovations into their artificial intelligence platform. With these actions, Salesforce positions itself for continued growth and expansion of its artificial intelligence offerings, while always maintaining high standards in efficiency and cost-effectiveness.
Source: MiMub in Spanish








