
Sure! Here’s the translation to American English:
—
Amazon has introduced an innovative feature on its artificial intelligence platform, SageMaker AI, now allowing for fine-tuning of GPT-OSS models using SageMaker HyperPod recipes and training jobs. This launch is part of a series of updates aimed at optimizing the use of these models for structured reasoning in multiple languages.
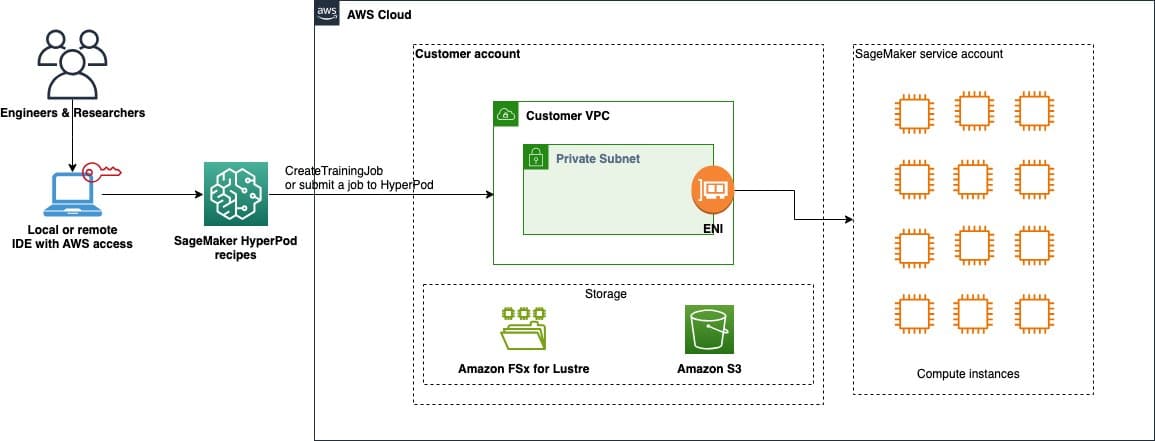
In the first installment, it was demonstrated how to fine-tune GPT-OSS models using the open-source libraries from Hugging Face in conjunction with SageMaker. With this new feature, SageMaker HyperPod recipes provide a simple and quick solution to kickstart the training and optimization of artificial intelligence models, such as Meta’s Llama and Mistral. These recipes come with predefined and validated configurations that simplify the creation of distributed training environments, ensuring enterprise-level performance and scalability.
The implementation relies on the use of SageMaker HyperPod to carry out fine-tuning jobs, managing orchestration via Amazon Elastic Kubernetes Service (EKS). To maximize the benefits of this functionality, organizations must set up a local development environment with AWS credentials and prepare several instances of the ml.p5.48xlarge type.
Fine-tuning involves preparing an appropriate dataset, such as the “HuggingFaceH4/Multilingual-Thinking” dataset, which is designed for reasoning examples in various languages. After tokenization and data preparation, recipes can be used to initiate the fine-tuning job, followed by deploying the trained model on a SageMaker endpoint for evaluation.
Experts emphasize that the SageMaker platform not only optimizes model training with temporary resources but also provides a persistent environment for continuous development through HyperPod, allowing organizations to experiment with models more effectively.
The final deployment of fine-tuned models is accomplished using optimized containers in Amazon Elastic Container Registry (ECR), ensuring that applications have access to the necessary resources to run real-time inferences. SageMaker also offers the capability to translate configurations and prepare variables for optimal performance.
This new functionality opens a promising horizon for organizations of various sizes to fully leverage the potential of large language models, facilitating the fine-tuning and deployment of custom models in an accessible manner. Developers interested in this technology can find guides and resources in Amazon’s GitHub repositories, which provide examples and detailed documentation.
—
Referrer: MiMub in Spanish








