
Kubernetes is a popular orchestration platform for container management, ideal for handling the variable workloads typical of machine learning (ML) applications, thanks to its scalability and load balancing capabilities. DevOps engineers often use Kubernetes to manage and scale ML applications. However, before an ML model is available, it must be trained and evaluated, and if a satisfactory quality model is obtained, it is uploaded to a model registry.
Amazon SageMaker makes it easy to eliminate the heavy lifting of building and deploying ML models. SageMaker simplifies dependency management, container images, automatic scaling, and monitoring. Specifically, for the model building stage, Amazon SageMaker Pipelines automates the process by managing the infrastructure and resources needed to process data, train models, and run evaluation tests.
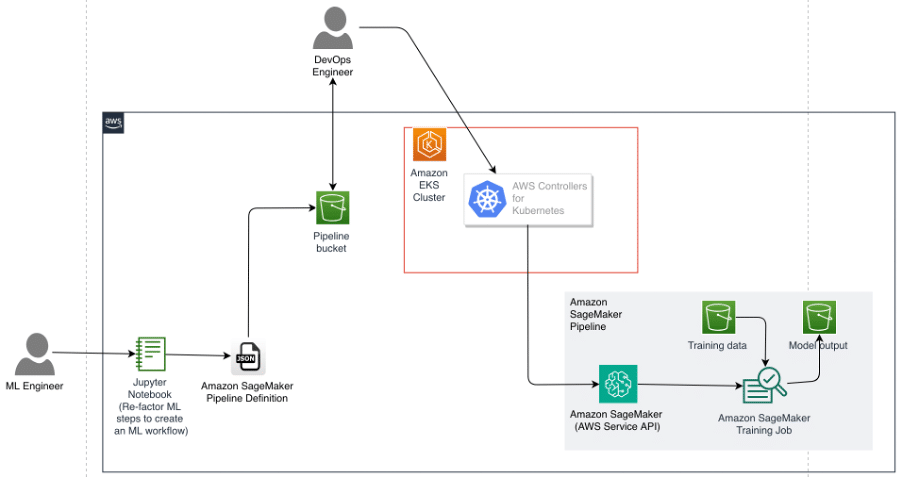
A challenge for DevOps engineers is the additional complexity that arises when using Kubernetes to manage the deployment stage, while resorting to other tools (such as the AWS SDK or AWS CloudFormation) to manage the model building pipeline. An alternative to simplify this process is to use AWS Controllers for Kubernetes (ACK) to manage and deploy a SageMaker training pipeline. ACK allows leveraging managed model building pipelines without the need to define resources outside the Kubernetes cluster.
In this article, we introduce an example to help DevOps engineers manage the entire ML lifecycle, including training and inference, using the same tool.
Solution Description
Consider a scenario where an ML engineer sets up a model building pipeline in SageMaker using a Jupyter notebook. This setup takes the form of a Directed Acyclic Graph (DAG) represented as a pipeline definition in JSON. The JSON document can be stored and versioned in an Amazon Simple Storage Service (Amazon S3) bucket. If encryption is required, it can be implemented using a key managed by AWS Key Management Service (AWS KMS) for Amazon S3. A DevOps engineer with access to retrieve this definition file from Amazon S3 can load the pipeline definition into an ACK service controller for SageMaker, which runs as part of an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The DevOps engineer can then use the Kubernetes APIs provided by ACK to submit the pipeline definition and start one or more pipeline executions in SageMaker.
To follow this process, some prerequisites must be met, such as having an EKS cluster, a user with access to an appropriate IAM role, and command-line tools installed on the local machine or cloud-based development environment.
Installation of the SageMaker ACK service controller
The SageMaker ACK service controller makes it easy for DevOps engineers to use Kubernetes as their control plane to create and manage ML pipelines. To install the controller in the EKS cluster, IAM permissions must be configured, the controller must be installed using a SageMaker Helm Chart, and the provided tutorial must be followed step by step.
Generating a pipeline definition in JSON
ML engineers are often responsible for creating ML pipelines in their organizations, working together with DevOps engineers to operate those pipelines. In SageMaker, ML engineers can use the SageMaker Python SDK to generate a pipeline definition in JSON format, following a predefined schema, which is retrieved to deploy and maintain the necessary infrastructure for the pipeline.
Creating and submitting a pipeline specification in YAML
In the world of Kubernetes, objects are persistent entities used to represent the state of the cluster. When creating an object in Kubernetes, a specification of the object describing its desired state must be provided in a YAML (or JSON) manifest file to communicate with the Kubernetes API.
To submit a pipeline specification in YAML and its execution, DevOps engineers must modify and prepare the appropriate YAML files and apply them in the Kubernetes cluster using command-line tools.
Reviewing and troubleshooting pipeline execution
Engineers can list all created pipelines and their executions, as well as review details about the pipeline and troubleshoot using specific kubectl commands.
Conclusion
We have presented an example of how ML engineers familiar with Jupyter notebooks and SageMaker environments can efficiently collaborate with DevOps engineers familiar with Kubernetes to design and maintain an ML pipeline with the proper infrastructure for their organization. This allows DevOps engineers to manage all steps of the ML lifecycle with the same set of tools and environment, enabling organizations to innovate faster and more efficiently.
Referrer: MiMub in Spanish









