
Here’s the translation to American English:
—
The choice of the right language model for specific applications has become a crucial challenge for organizations. Many teams employ informal assessments, relying on personal impressions and limited samples of popular models, which can lead to hasty decisions. This informal approach often fails to detect subtle errors or insecure behaviors in the model’s responses.
A more rigorous evaluation method involves using both qualitative and quantitative metrics, assessing aspects like the quality of responses, cost, and performance. However, current evaluation systems often aren’t scalable enough for businesses to fully leverage the multiple model options available. Therefore, having a structured process to guide organizations in their selection becomes essential.
Impression-based evaluations can be problematic, as they are often influenced by subjective biases. Evaluators might prefer responses that are more aesthetically pleasing but not necessarily accurate. Additionally, by limiting themselves to a few examples, the complexity of real-world inputs can be overlooked, potentially missing cases that could reveal critical weaknesses in the model. The lack of a clear reference framework further complicates aligning model choice with an organization’s business objectives.
While benchmarks like MMLU and HellaSwag provide standardized assessments in areas like reasoning, they tend to focus on overall performance rather than specific domains. This can lead to situations where a model that scores highly on trivial tasks may not be effective in specialized contexts, potentially resulting in incorrect or disproportionate responses.
To conduct a proper evaluation, it is vital to consider multiple dimensions, including accuracy, latency, and cost efficiency. This way, confidence in the model can be enhanced, and a more detailed analysis obtained. By combining quantitative metrics with qualitative assessments, a more effective evaluation can be achieved.
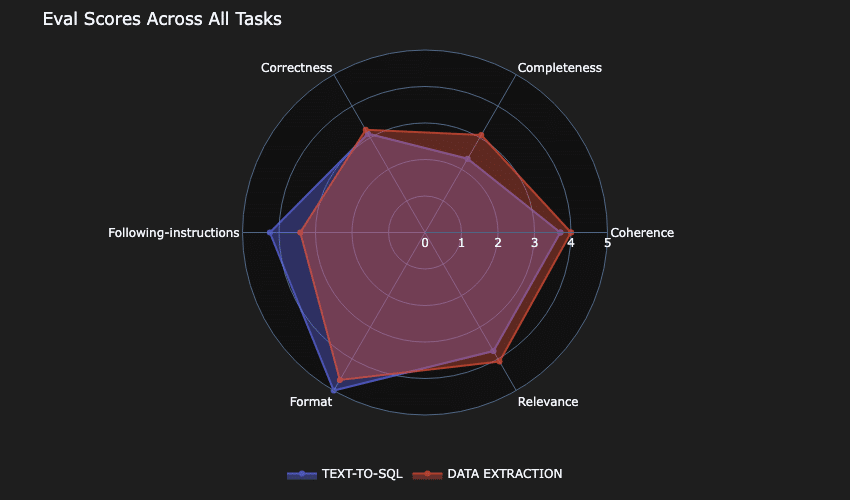
A new initiative called 360-Eval seeks to automate the evaluation process by providing a tool that captures the extensive performance capabilities of the model. This will allow companies like AnyCompany to comprehensively assess different LLM models, applying criteria that highlight not only accuracy but also cost and efficiency.
A practical case is AnyCompany’s development of a SaaS solution that improves database architecture. The tool is designed to receive requirements in natural language and automatically create specific data models for PostgreSQL. The evaluation of different language models focuses on ensuring quick and cost-effective responses while maintaining the necessary quality.
Ultimately, the choice of model is based on its ability to meet performance, cost, and accuracy criteria. This approach not only allows for informed decisions but also helps organizations adapt swiftly to changing market needs. In a rapidly evolving field like generative artificial intelligence, establishing a solid evaluation infrastructure is essential for identifying the right model for each specific case.
—
via: MiMub in Spanish








