
The technique of Retrieval-Augmented Generation (RAG) has emerged as a powerful tool for enhancing the capabilities of large language models (LLMs). By combining the vast knowledge stored in external data sources with the generative power of LLMs, RAG allows for addressing complex tasks that require both knowledge and creativity. Nowadays, RAG techniques are used in companies of all scales, where generative artificial intelligence is employed to answer questions based on documents and other types of analysis.
While building a simple RAG system is straightforward, developing production RAG systems using advanced patterns poses a challenge. A production RAG pipeline typically operates on a larger volume of data and with higher data complexity, and must meet a higher quality standard compared to building a proof of concept. A common challenge faced by developers is low response quality; the RAG pipeline is not able to adequately answer a large number of questions, which may be due to various reasons such as:
- Incorrect retrievals – Lack of relevant context needed to answer the question.
- Incomplete answers – Relevant context is partially present but not fully. The generated output does not fully answer the input question.
- Hallucinations – Relevant context is present, but the model is unable to extract the relevant information to answer the question.
This requires more advanced RAG techniques in the query understanding, retrieval, and generation components to handle these failure modes.
This is where LlamaIndex comes in, an open-source library with both simple and advanced techniques that enables developers to build production RAG pipelines. It provides a flexible and modular framework for building and querying document indexes, integrating with various LLMs, and implementing advanced RAG patterns.
Amazon Bedrock is a managed service that provides access to high-performance foundational models from leading AI providers through a unified API. It offers a wide range of large models to choose from, along with capabilities to securely build and customize generative AI applications. Key advanced features include model customization with fine-tuning and continuous training using your own data, as well as RAG to enhance model outputs by retrieving context from configured knowledge bases containing your private data sources. Other enterprise capabilities include guaranteed performance for low-latency scale inferences, model evaluation to compare performance, and AI safeguards to implement security measures.
In this article, we explore how to use LlamaIndex to build advanced RAG pipelines with Amazon Bedrock. We discuss how to configure the following:
- Simple RAG pipeline – Setting up a RAG pipeline in LlamaIndex with Amazon Bedrock models and top-k vector search.
- Routing query – Adding an automated router that can dynamically perform semantic (top-k) searches or summaries on data.
- Sub-question querying – Adding a query decomposition layer that can break down complex queries into multiple simpler ones and execute them with relevant tools.
- Agency RAG – Building a stateful agent that can perform the previous components (tool usage, query decomposition) but also maintain a conversation history and reasoning over time.
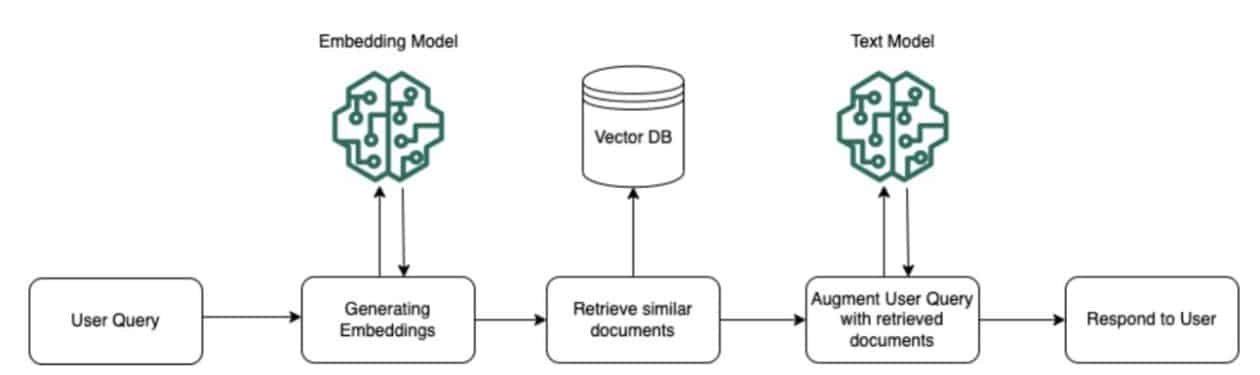
At its core, RAG involves retrieving relevant information from external data sources and using it to augment prompts fed to an LLM. This allows the LLM to generate responses based on factual knowledge and tailored to the specific query. For RAG workflows in Amazon Bedrock, configured knowledge base documents undergo preprocessing, where they are split into fragments, embedded into vectors, and indexed in a vector database. This enables efficient retrieval of relevant information at runtime. When a user query arrives, the same embedding model is used to convert the query text into a vector representation. This query vector is compared to the indexed document vectors to identify the most semantically similar fragments from the knowledge base. These fragments provide additional context related to the user query and are added to the original prompt before being passed to the foundational model to generate a response.
LlamaCloud and LlamaParse represent the latest advancements in the LlamaIndex ecosystem, with LlamaCloud offering a comprehensive set of managed services for enterprise-level context augmentation and LlamaParse acting as a specialized document analysis engine for complex documents. These services enable efficient management of large production data volumes, improving response quality, and unlocking unprecedented capabilities in RAG applications.
Finally, integrating Amazon Bedrock and LlamaIndex to build an advanced RAG stack can be accomplished through several precise steps, from downloading source documents to the final index query with a specific question. This advanced setup promises to streamline the management of large data volumes and significantly enhance the quality of responses generated by LLMs in complex contexts.
In conclusion, by combining the capabilities of LlamaIndex and Amazon Bedrock, companies can build robust and sophisticated RAG pipelines that maximize the potential of LLMs for knowledge-intensive tasks.
via: AWS machine learning blog
via: MiMub in Spanish








