
Information retrieval systems have driven the information age by their ability to track and filter large amounts of data, returning accurate and relevant results quickly. These systems, such as search engines and databases, typically work by indexing keywords and fields contained in data files.
However, much of our data in the digital age also comes in non-textual formats, such as audio and video files. Finding relevant content often requires searching through text-based metadata, such as timestamps, which must be manually added to these files. This can be challenging to scale as the volume of unstructured audio and video files continues to grow.
Fortunately, the rise of artificial intelligence (AI) solutions that can transcribe audio and provide semantic search capabilities now offers more efficient solutions for querying audio files at scale. Amazon Transcribe is an AWS service that facilitates speech-to-text conversion. Amazon Bedrock is a fully-managed service that offers a selection of high-performance foundational AI models from leading companies through a single API, along with a wide range of capabilities for building generative AI applications with security, privacy, and responsible AI.
In this article, we show how Amazon Transcribe and Amazon Bedrock can simplify the process of cataloging, querying, and searching through audio programs, using an example from the AWS re:Think podcast series.
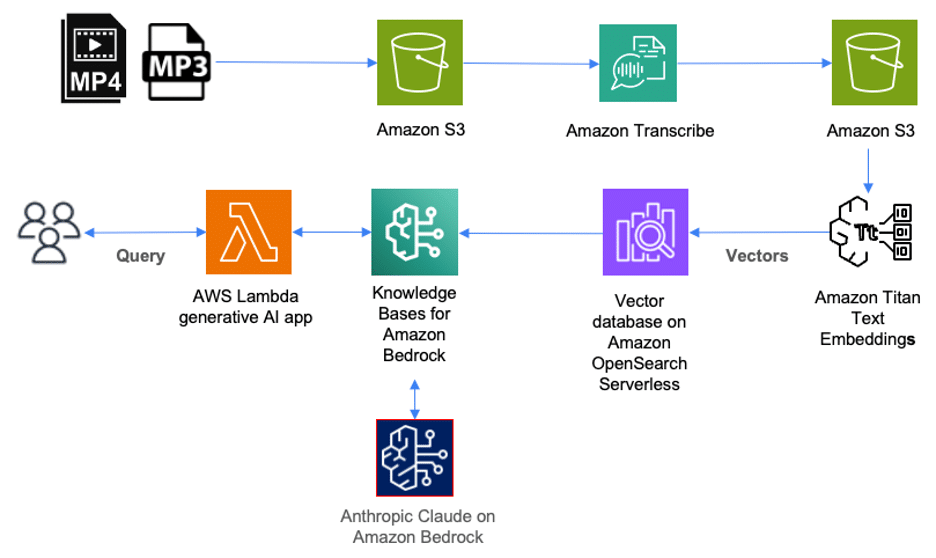
The following solution illustrates how you can use AWS services to deploy a solution for cataloging, querying, and searching through content stored in audio files. Audio files in mp3 format are first uploaded to Amazon Simple Storage Service (Amazon S3). Video files (such as mp4) containing audio in supported languages can also be uploaded to Amazon S3 as part of this solution. Amazon Transcribe will then transcribe these files and store the full transcription in JSON format as an object in Amazon S3.
To catalog these files, each JSON file in Amazon S3 must be tagged with the corresponding episode title. This allows us to retrieve the episode title for each query result. We then use Amazon Bedrock to create numerical representations of the content within each file, also called embeddings, which are stored as vectors in a vector database that we can query later.
Amazon Bedrock is a fully managed service that makes foundational models from leading AI startups and Amazon available through an API. Included with Amazon Bedrock are the Knowledge Bases for Amazon Bedrock. As a fully managed service, the Knowledge Bases for Amazon Bedrock make it easy to set up an Augmented Generation Retrieval (AGR) workflow.
With the Knowledge Bases for Amazon Bedrock, we first set up a vector database on AWS. Then, this service can automatically split the data files stored in Amazon S3 into shards, and create embeddings of each shard using Amazon Titan on Amazon Bedrock. Amazon Titan is a family of high-performance foundational models from Amazon. Along with Amazon Titan come the Titan Text Embeddings, which we use to create the numerical representation of the text within each shard and store them in a vector database.
When a user queries the content of the audio files through a generative AI application or an AWS Lambda function, an API call is made to the Knowledge Bases for Amazon Bedrock. This service organizes a call to the vector database to perform a semantic search, returning the most relevant results. The Knowledge Bases for Amazon Bedrock then augment the user’s original query with these results to a prompt, which is sent to the large language model (LLM). The LLM returns results that are more accurate and relevant to the user’s query.
For this example, we use episodes from the AWS re:Think podcast series, with over 20 episodes. Each episode is an audio program recorded in mp3 format. As we continue to add new episodes, we want to use AI services to make the task of querying and searching for specific content more scalable without the need to manually add metadata for each episode.
First, we need a library of audio files to catalog, query, and search. For this example, we use episodes from the AWS re:Think podcast series. To make API calls to Amazon Bedrock from our generative AI application, we use Python version 3.11.4 and the AWS SDK for Python (Boto3).
The first step is to transcribe each mp3 file using Amazon Transcribe. For instructions on transcriptions with the AWS management console or AWS CLI, refer to the Amazon Transcribe developer guide. Amazon Transcribe can create a transcription for each episode and store it as an S3 object in JSON format.
To catalog each episode, we tag the S3 object for each episode with the corresponding episode title. For instructions on tagging objects in S3, refer to the Amazon Simple Storage Service user guide. In this example, simply add the “title” tag with the corresponding episode title value.
Next, we set up our managed AGR workflow using the Knowledge Bases for Amazon Bedrock. For instructions on creating a knowledge base, refer to the Amazon Bedrock user guide. We start by specifying a data source. In our case, we choose the location of the S3 bucket where our transcriptions are stored in JSON format. We select an embedding model to convert each shard of our transcription into embeddings.
The embeddings are stored as vectors in a vector database. You can specify an existing vector database or have the Knowledge Bases for Amazon Bedrock create one for you. In this example, we opt for the service to create a vector database using Amazon OpenSearch Serverless.
To make a query, we first synchronize the vector database with the data source. During each synchronization operation, the Knowledge Bases for Amazon Bedrock divide the data source into shards and use the selected embedding model to embed each shard as a vector.
Then, we are ready to query and search for specific content from our podcast episode library. For example, we ask why AWS acquired Annapurna Labs, and we get a precise answer directly from a quote in the episode.
Finally, through additional API calls, we can retrieve the relevant episode title and start time of the relevant content within the episode, thus optimizing the search experience without the need for extensive manual metadata.
At the end of the process, it is important to clean up the resources used to avoid unnecessary costs, as the services operate under a pay-as-you-go model.
Organizing, querying, and searching through large volumes of audio files can be difficult to scale. This example demonstrates how Amazon Transcribe and the Knowledge Bases for Amazon Bedrock can help automate and make the process of retrieving relevant information from audio files more scalable.
You can start transcribing your own library of audio files with Amazon Transcribe and use the Knowledge Bases for Amazon Bedrock to automate the AGR workflow for your transcriptions with vector stores. With the help of these AI services, we can now expand the boundaries of our knowledge base.
via: AWS machine learning blog
Source: MiMub in Spanish








