
Large Language Models (LLMs) are revolutionizing Natural Language Processing (NLP) by being applied to tasks ranging from simple dialogues to complex decision-making and summary generation. However, precise alignment of these models with user intentions remains a challenge, as methods such as prompt engineering and supervised fine-tuning often prove insufficient. These approaches can lead to unwanted behaviors, including the generation of incorrect information and biased or toxic content.
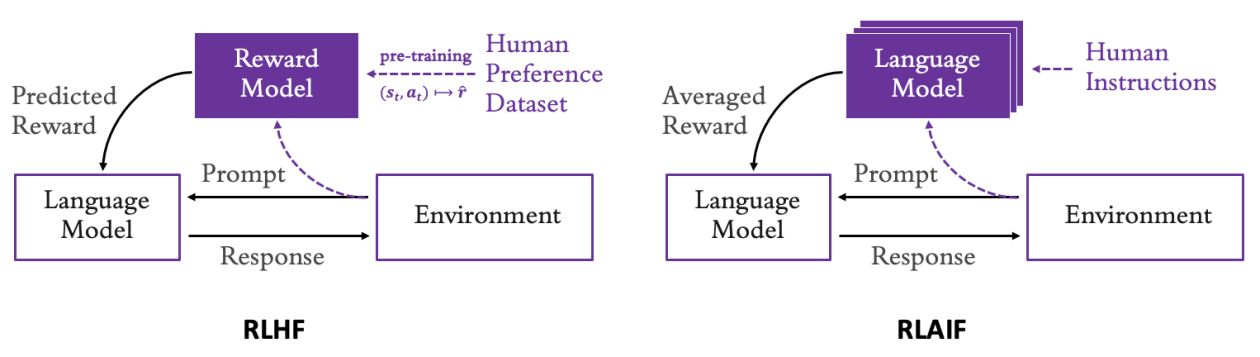
Supervised fine-tuning, while helpful, does not capture the ethical and social nuances that are difficult to translate into simple examples, which can cause models to act contrary to expectations. In response to this issue, a promising alternative has emerged: the use of reward models trained from human feedback, known as Reinforcement Learning with Human Feedback (RLHF). This method allows for adjusting LLM behaviors based on human preferences and values.
However, recent studies suggest that feedback provided by other language models may be equally effective in scaling the development of reward models, a technique known as Superalignment using AI Feedback (RLAIF). This methodology allows for implementing multiple LLMs, each specialized in different human preferences such as relevance, conciseness, or toxicity. This eliminates the need for human annotation services, thus optimizing the development process.
A use case for RLAIF could involve generating responses in a dialogue dataset, focusing on reducing toxicity in the produced responses. This can be done by using publicly available reward models to fine-tune the LLMs, and then evaluating the success of the adjustments through a reserved dataset.
This development in LLM tuning shows that the field is dynamic and constantly evolving. Techniques like RLAIF offer valuable opportunities to improve the alignment of artificial intelligence with human preferences and values, ensuring more useful and less harmful responses. The continuity of research in this area becomes crucial in addressing the ethical and technical challenges that artificial intelligence presents today.
via: MiMub in Spanish








