
With the arrival of generative artificial intelligence solutions, a paradigm shift is taking place in various industries, driven by organizations adopting baseline models to unlock unprecedented opportunities. Amazon Bedrock has established itself as the preferred choice for numerous clients looking to innovate and launch generative AI applications, leading to an exponential increase in demand for model inference capabilities. Bedrock customers aim to scale their applications globally to accommodate growth and require additional capacity to handle unexpected traffic spikes. Currently, users may have to design their applications to handle traffic spike scenarios, using multi-region service quotas through complex techniques like client-side load balancing between AWS regions. However, this dynamic nature of demand is difficult to predict, increases operational overhead, and introduces potential points of failure, which can prevent businesses from achieving true global resilience and continuous service availability.
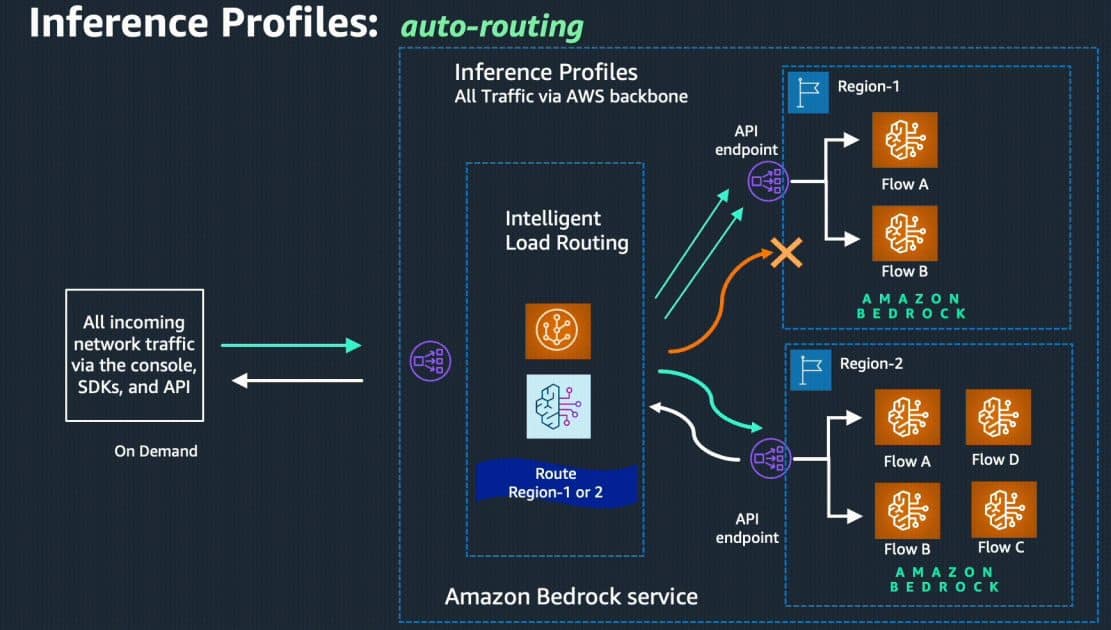
Today, we are pleased to announce the general availability of cross-region inference, a powerful feature that enables automatic routing of inferences between regions for requests coming to Amazon Bedrock. This provides developers using on-demand inference mode a seamless solution for optimally managing availability, performance, and resilience while handling traffic spikes in Amazon Bedrock-powered applications. By opting for this feature, developers no longer have to spend time and effort predicting demand fluctuations. Instead, cross-region inference dynamically routes traffic across multiple regions, ensuring optimal availability for each request and smoother performance during periods of high utilization. Furthermore, this capability prioritizes the source/primary region of the Amazon Bedrock API whenever possible, helping to minimize latency and improve responsiveness. As a result, customers can enhance the reliability, performance, and efficiency of their applications.
Let’s delve into this functionality:
Some key features of cross-region inference include:
– Utilization of AWS’s multi-region capacity, allowing scaling of generative AI workloads with demand.
– Compatibility with Amazon Bedrock’s existing API.
– No additional routing or data transfer costs.
– Increased resilience to traffic spikes.
– Ability to choose from a range of pre-configured region sets tailored to user needs.
To start using this functionality, users must leverage inference profiles in Amazon Bedrock, which configure different model ARNs from respective AWS regions and abstract them behind a unified model identifier. Simply by using this new inference profile identifier with the InvokeModel or Converse API, developers can take advantage of cross-region inference.
For those interested in implementing this new capability, it is essential to carefully evaluate the application requirements, traffic patterns, and existing infrastructure. For example, current workloads and traffic patterns should be analyzed, potential benefits of cross-region inference evaluated, applications migrated and developed taking this functionality into account from the outset.
In conclusion, Amazon Bedrock’s cross-region inference provides developers with a powerful tool to enhance the reliability, performance, and efficiency of their applications without significant efforts in building complex resilience structures. This functionality is already available in the US and EU for supported models, marking a significant advancement in traffic management and availability capabilities for generative AI applications.
via: MiMub in Spanish








