Music generation models have emerged as powerful tools that transform natural language text into musical compositions. Originating from advances in artificial intelligence (AI) and deep learning, these models are designed to understand and translate descriptive text into coherent and aesthetically pleasing music. Their ability to democratize music production allows individuals without formal training to create high-quality music simply by describing their desires.
Generative AI models are revolutionizing the creation and consumption of music. Companies can leverage this technology to develop new products, streamline processes, and explore untapped potentials, making a significant impact on businesses. These music generation models enable diverse applications, from custom soundtracks for multimedia and video games to educational resources for students exploring musical styles and structures. They assist artists and composers by providing new ideas and compositions, fostering creativity and collaboration.
An outstanding example of a music generation model is Meta’s AudioCraft MusicGen. The code for MusicGen is released under MIT, and the model weights under CC-BY-NC 4.0. MusicGen can create music based on text inputs or melody, providing better control over the outcome. MusicGen uses cutting-edge AI technology to generate diverse musical styles and genres, catering to various creative needs. Unlike traditional methods that involve cascading multiple models, such as hierarchically or through oversampling, MusicGen operates as a single language model handling various streams of discrete compressed musical representations (tokens). This simplified approach empowers users with precise control over generating high-quality mono and stereo samples tailored to their preferences, revolutionizing AI-driven music composition.
MusicGen models can be used in education, content creation, and music composition. They allow students to experiment with different musical styles, generate custom soundtracks for multimedia projects, and create personalized musical compositions. Additionally, MusicGen can assist musicians and composers, fostering creativity and innovation.
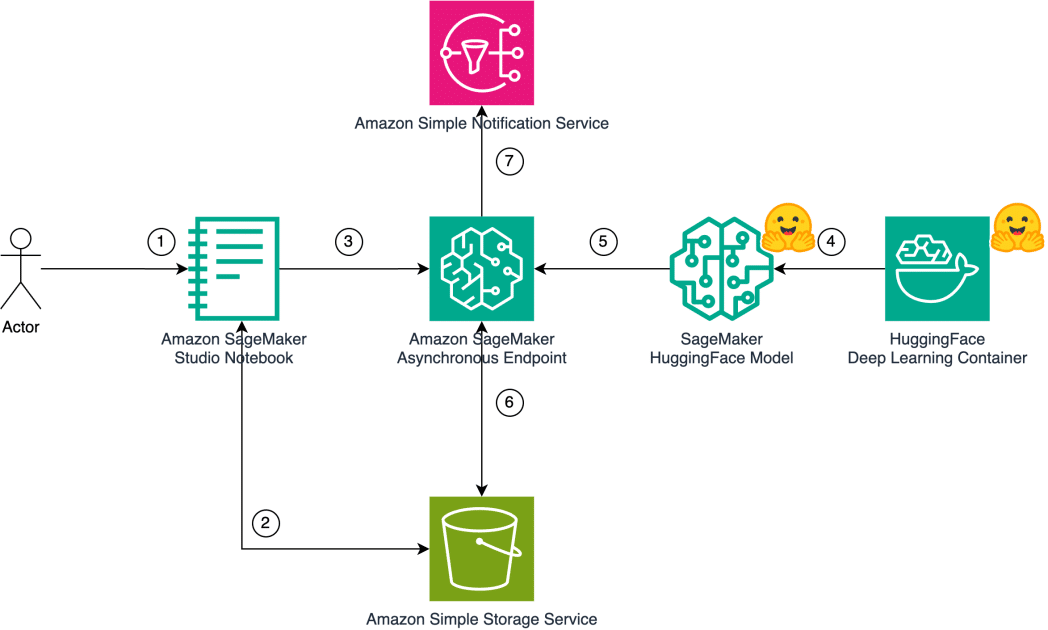
Implementing MusicGen, a music generation model on Amazon SageMaker using asynchronous inference, can be particularly effective. This approach involves deploying AudioCraft MusicGen models obtained from the Hugging Face Model Hub on a SageMaker infrastructure. The architecture of this solution demonstrates how a user can generate music using natural language text as input command through AudioCraft MusicGen models deployed on SageMaker.
The steps detail the sequence from the moment the user inputs the command to the point where music is generated as output. Configuring these elements makes it possible to increase efficiency and maximize available resources, especially through automatic scalability of SageMaker’s asynchronous inference instances.
For those looking to explore these capabilities and start generating music from their creative prompts, this tool offers an accessible and highly sophisticated path for musical innovation with AI. Those interested in implementing this model can find the complete source code and additional details in the official GitHub repositories.
via: MiMub in Spanish