
Large Language Models (LLMs) have emerged as promising tools in the field of machine translation, showcasing capabilities that could rival those of neural translation models like Amazon Translate. This advancement is largely due to their innate ability to learn from the context in which they are placed, allowing them to interpret cultural nuances and produce translations that sound more natural.
Translation is not merely a mechanical process; variations in context can significantly alter the meaning of a phrase. For instance, the question “Did you perform well?” can be transformed into a more precise formulation depending on the context in which it is used, such as in sports, or in other cultural contexts. Recognizing these particularities is key for AI to achieve smooth and accurate translations.
As the demand for high-quality translation solutions increases globally, many clients are looking to leverage the effectiveness of LLMs. These models are integrated into a process called Machine Translation with Post-Editing (MTPE), which combines the power of automation with human intervention. This synergy not only reduces costs in MTPE activities, but also promises faster delivery times and enhances user experience.
However, the use of LLMs in machine translation is not without challenges. Inconsistencies in translation quality have been observed, particularly between certain language pairs, as well as the lack of a standard for integrating translation memory, which can result in significant errors in the process. Additionally, the phenomenon known as “hallucination” can lead LLMs to generate outputs that have no basis in real context.
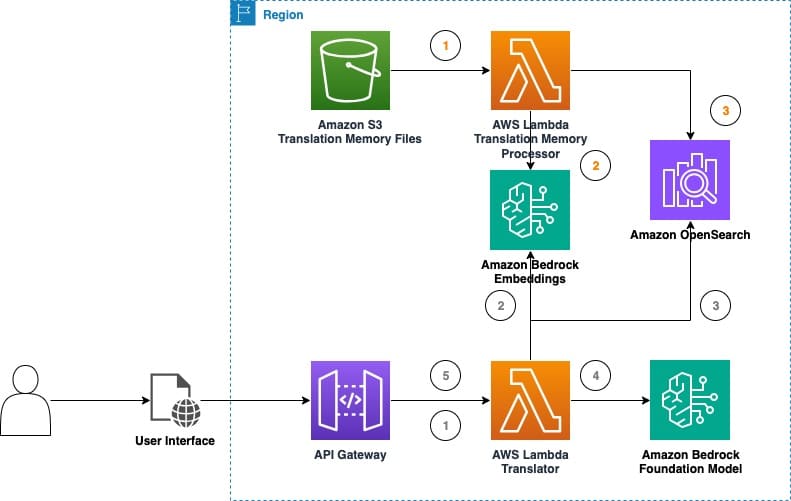
The industry is beginning to recognize the potential of LLMs for translation tasks, although the approach must be careful and specific to each case. In this sense, a solution has been developed that uses Amazon Bedrock to experiment with real-time machine translation, allowing for the collection of data on the effectiveness of LLMs in content translation applications. This solution implements translation memory techniques, a tool that stores previously translated text segments, facilitating the work of translators and increasing their efficiency.
Combining translation memory with LLMs could revolutionize the quality and efficiency of machine translation. By leveraging stored high-quality translations, LLMs could ensure greater accuracy and consistency. Likewise, translation memories containing domain-specific data can help models better adapt to the required vocabulary and style.
Furthermore, the use of these memories can reduce effort in post-editing, resulting in increased productivity and significant savings. The integration of these tools with LLMs is feasible without drastic operational complications, making it easier for companies to implement existing models.
A recent tool called “LLM Translation Testbed” allows users to evaluate and experiment with the translation capabilities of LLMs. This platform offers various tools, such as the ability to create and compare inference configurations and evaluate the effectiveness of prompt engineering.
Initial tests have shown that LLMs can effectively adapt to context, significantly improving the quality of translation. Through experiments with translation memory, a notable increase in the quality of translations has been observed, underscoring the importance of this combination of technologies for future localization projects.
In conclusion, the ongoing research and development of LLMs for machine translation not only promise to improve the quality of translations, but also aim to make the localization process more efficient and accessible for companies of all sizes.
via: MiMub in Spanish









