
Sure, here’s the translation into American English:
—
In the field of video and image analysis, many companies face the challenge of detecting objects that were not present in the training set of a specific model. This situation becomes even more complicated in dynamic environments where new, unknown, or user-defined objects emerge. For example, media editors may want to track emerging brands or products in user-generated content; advertisers need to analyze the appearance of products in influencer videos, despite visual variations; retail providers aim to facilitate flexible, descriptive searches; autonomous vehicles must identify unexpected debris on the road; and manufacturing systems need to recognize novel or subtle defects that have not been previously labeled.
Traditional closed-set object detection models (CSOD), which only recognize a fixed list of predefined categories, are often ineffective in these scenarios. Such models tend to misclassify unknown objects or ignore them altogether, thereby limiting their usefulness in real-world applications. In this context, open-set object detection (OSOD) emerges as a solution that allows for the detection of both known objects and those that have not been previously observed, including those not included in the training. OSOD supports input of flexible prompts, from specific object names to open descriptions, adapting to user-defined objectives in real time without the need for retraining.
Amazon Bedrock Data Automation emerges as a cloud service capable of extracting insights from unstructured content such as documents, images, videos, and audio. With regard to video content, Bedrock Data Automation offers advanced capabilities such as chapter segmentation, frame-level text detection, classification according to Interactive Advertising Bureau (IAB) taxonomies, and frame-level object detection using OSOD.
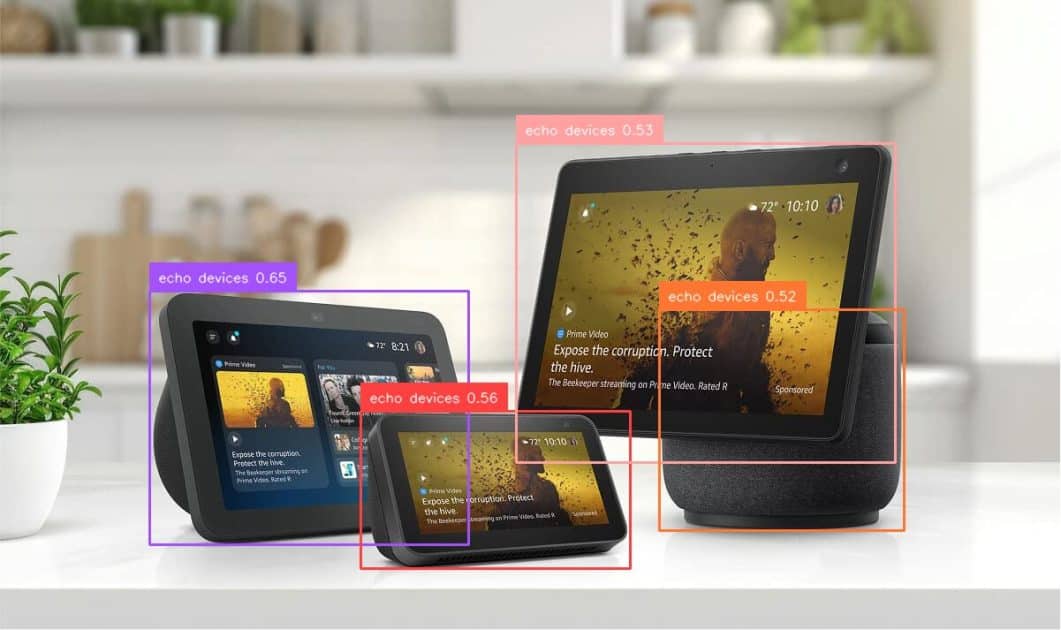
Amazon Bedrock Data Automation’s video templates are compatible with OSOD at the frame level. By inputting a video along with text specifying the objects to detect, the model generates a dictionary that includes XYWH coordinates of bounding boxes, as well as labels and confidence scores. Additionally, users can customize the output according to their needs, filtering for high-confidence detections when maintaining precision is a priority.
This functionality presents multiple applications. For example, advertisers can analyze the effectiveness of various ad placement strategies and conduct A/B testing to identify the most effective advertising approach. OSOD can also be utilized to develop intelligent resizing strategies, ensuring that important visual information is preserved when detecting key elements in the video. In home security systems, producers can leverage the model’s understanding and localization capabilities to ensure a safe environment. Furthermore, users can define custom labels and perform searches within videos to retrieve specific results. With text-based flexible detection, editors can accurately remove or replace objects, reducing the need for hand-drawn masks that often require multiple attempts.
The integration of OSOD within Amazon Bedrock Data Automation significantly enhances the ability to extract actionable insights from video content. By combining text-driven flexible queries with frame-level object localization, OSOD empowers users across various industries to implement intelligent video analysis workflows, ranging from assessing specific ads to security surveillance and tracking custom objects. This integration not only optimizes content understanding but also reduces the need for manual intervention and rigid predefined schemes, making it a valuable resource for real-world applications.
—
If you need further refinements or changes, feel free to ask!
Referrer: MiMub in Spanish









