
Sure! Here’s the translation into American English:
—
Generative artificial intelligence has evolved from being a mere curiosity to becoming an essential resource for innovation across multiple sectors. Its ability to synthesize complex legal documents and develop sophisticated virtual assistants has transformed various fields. However, despite advancements in language models, the quality of data remains crucial for making a significant impact in the real world.
A year ago, differentiation in generative AI applications revolved around who could create or use the largest model. However, with the decreasing costs of training models like DeepSeek-R1 and improvements in cost-performance ratios, powerful models are becoming more accessible. This new landscape has revealed that true success in generative AI is increasingly tied to access to high-quality data.
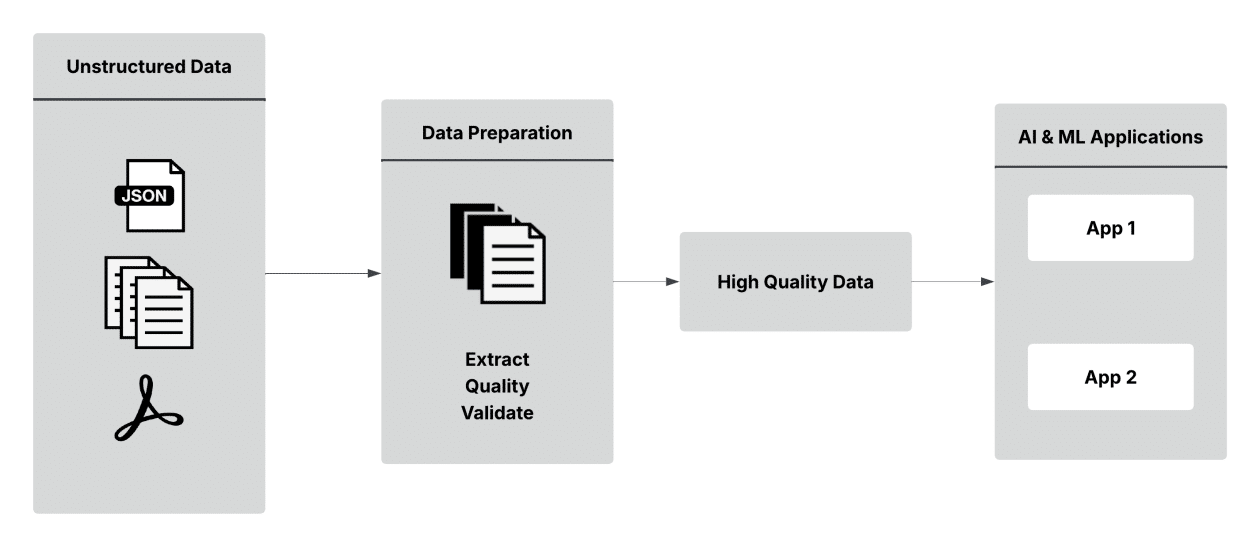
Organizations that have accumulated large volumes of unstructured data over decades face the challenge of leveraging this information. Elements such as call transcripts, scanned reports, and social media records must be transformed and comply with strict regulations, which becomes vital when moving AI from testing to real-world implementations.
Despite the rise in AI utilization, many business projects fail due to poor data quality and lack of proper controls. It is estimated that by 2025, 30% of generative AI projects will be abandoned, as even the most data-focused companies have overlooked unstructured content, which accounts for more than 80% of their available information.
For chief information and technology officers, managing unstructured data presents both challenges and opportunities. Data extraction and regulatory compliance are often manual tasks that are prone to errors and resource-intensive, further complicating existing workflows.
In this context, adopting solutions like Anomalo, in combination with Amazon Web Services (AWS), can be an effective path. These tools allow for the rapid and effective detection, isolation, and resolution of quality issues in unstructured data. Anomalo’s automated data ingestion and metadata extraction capabilities optimize the identification of irregularities and ensure regulatory compliance, thereby improving the quality of data used in business AI applications.
The implementation of such solutions could lead to a significant reduction in operational burden, cost optimization, and accelerated reporting and analytics. Integrating data quality into the core of AI applications will enable companies to increase their productivity and mitigate the risks associated with handling sensitive information.
In conclusion, the future of generative AI will largely depend on data quality. Organizations that can effectively structure and validate their information will be in a privileged position to take advantage of the opportunities provided by this emerging technology.
—
Let me know if you need any further modifications!
Source: MiMub in Spanish








