
Here’s the translation to American English:
In the current landscape of artificial intelligence, multimodal fine-tuning stands out as an essential technique for customizing language and vision models. This methodology allows for the adaptation of models to specific tasks that require the integration of visual and textual information. Although basic multimodal models deliver impressive performance, they often fall short in handling specialized tasks, such as processing complex documents or meeting specific output format requirements.
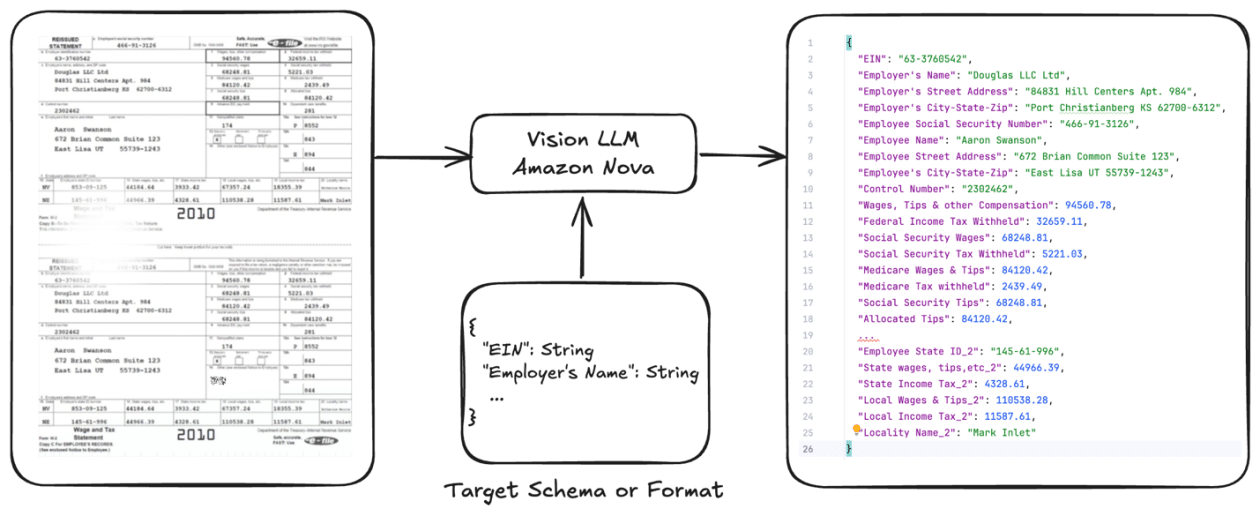
One of the most relevant applications of this technique is in the realm of document processing, where the goal is to extract structured information from various formats, including invoices, purchase orders, and technical forms. Conventional large language models (LLMs) often face challenges when dealing with specific documents, such as tax forms or loan applications. By implementing fine-tuning, these models can be adapted to enhance accuracy and reduce operational costs.
Recently, a practical guide has been developed to fine-tune Amazon Nova Lite specifically for document processing, placing a strong emphasis on extracting data from tax forms. This guide integrates an open-source repository on GitHub, detailing a workflow from data preparation to model deployment. With the support of Amazon Bedrock, companies can benefit from on-demand inference, allowing for model customization while maintaining a flexible cost structure.
The inherent challenges of document processing are significant. Extracting structured information from multi-page documents is a complex task, influenced by the variability of formats, the diversity of document types, data quality, and language barriers. This is especially critical when it concerns tax data, where high levels of precision are required.
Strategies for intelligent document processing are divided into three main categories: prompting without examples, prompting with examples, and fine-tuning. The fine-tuning option is the most suitable for personalizing LLMs based on specific tasks, facilitating the extraction or interpretation of relevant data.
Creating an annotated dataset and selecting the appropriate technique for customization are crucial elements. Supervised fine-tuning emerges as the best option when access to labeled data is available, allowing models to be tailored to specific tasks. Distillation approaches are also proposed, which enable creating more agile and efficient models by transferring knowledge from a more complex model to a simpler one.
Thanks to Amazon Bedrock, users with basic data science skills can implement fully managed fine-tuning tasks. Additionally, using Amazon SageMaker facilitates the promotion of Nova models, providing more options for customization.
Data preparation and quality are fundamental aspects for the success of fine-tuning. A thorough analysis of the dataset is recommended, along with evaluating the base model and optimizing prompts to align them with the job requirements.
Recent evaluations have shown significant improvements in accuracy and F1 scores across various categories thanks to the implementation of fine-tuning, achieving 100% recall rates in fine-tuned models. Moreover, Amazon Bedrock offers a transparent cost model, making it a cost-effective and scalable solution, enabling businesses to optimize their infrastructure without the need for complex capacity planning.
Source: MiMub in Spanish








